tweetopic
Blazing fast short-text-topic-modelling for Python.
tweetopic
:zap: Blazing Fast topic modelling over short texts in Python
![]()

Features
- Fast :zap:
- Scalable :collision:
- High consistency and coherence :dart:
- High quality topics :fire:
- Easy visualization and inspection :eyes:
- Full scikit-learn compatibility :nut_and_bolt:
New in version 0.4.0 ✨
You can now pass random_state to topic models to make your results reproducible.
from tweetopic import DMM
model = DMM(10, random_state=42)
🛠 Installation
Install from PyPI:
pip install tweetopic
👩💻 Usage (documentation)
Train your a topic model on a corpus of short texts:
from tweetopic import DMM
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.pipeline import Pipeline
# Creating a vectorizer for extracting document-term matrix from the
# text corpus.
vectorizer = CountVectorizer(min_df=15, max_df=0.1)
# Creating a Dirichlet Multinomial Mixture Model with 30 components
dmm = DMM(n_components=30, n_iterations=100, alpha=0.1, beta=0.1)
# Creating topic pipeline
pipeline = Pipeline([
("vectorizer", vectorizer),
("dmm", dmm),
])
You may fit the model with a stream of short texts:
pipeline.fit(texts)
To investigate internal structure of topics and their relations to words and indicidual documents we recommend using topicwizard.
Install it from PyPI:
pip install topic-wizard
Then visualize your topic model:
import topicwizard
topicwizard.visualize(pipeline=pipeline, corpus=texts)
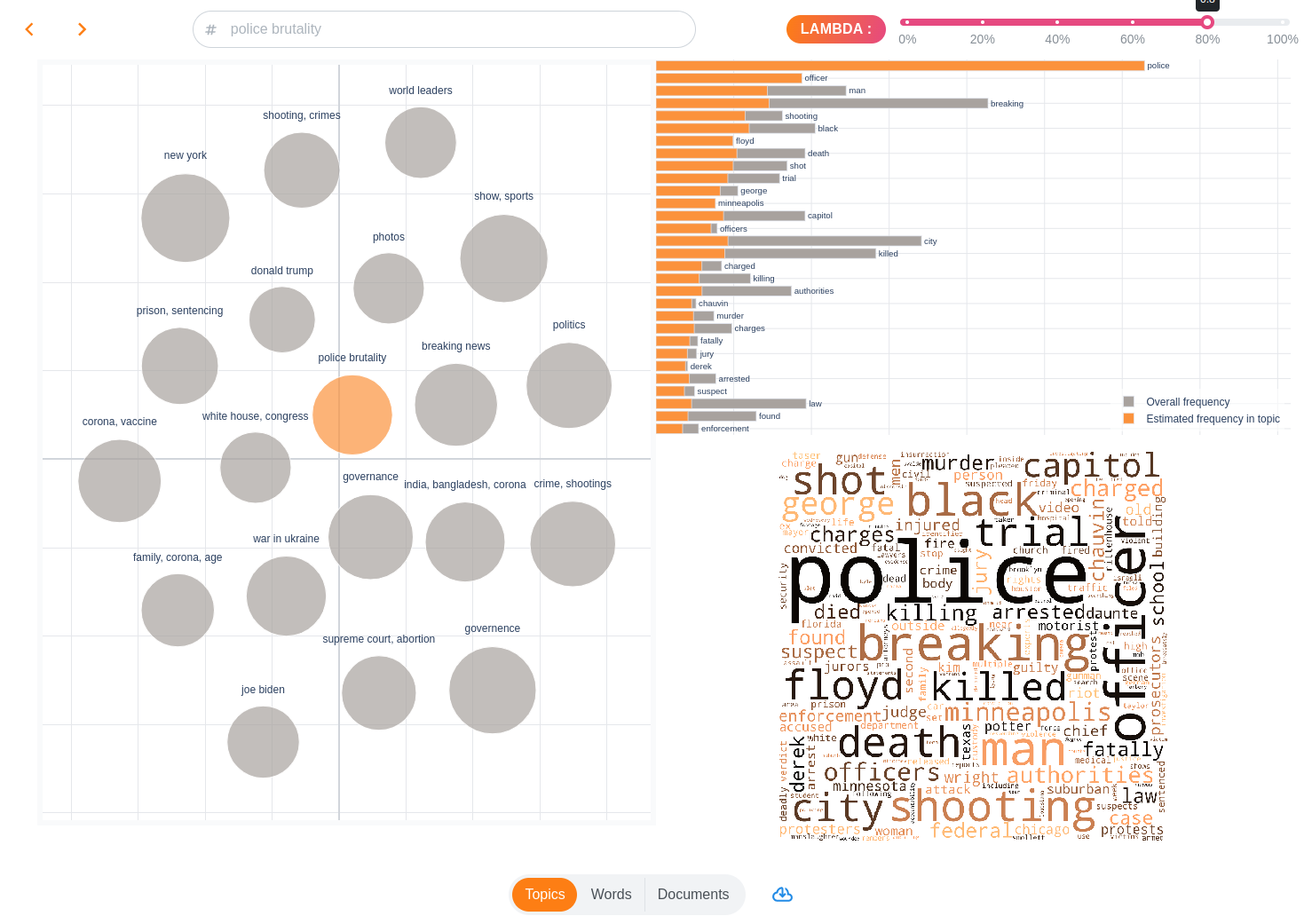
🎓 References
- Yin, J., & Wang, J. (2014). A Dirichlet Multinomial Mixture Model-Based Approach for Short Text Clustering. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 233–242). Association for Computing Machinery.