sq
Command line tool that provides jq-style access to structured data sources: SQL databases, or document formats like CSV or Excel. It is the lovechild of sql+jq.
![]()
![]()
![]()
sq data wrangler
sq is a command line tool that provides jq-style access to
structured data sources: SQL databases, or document formats like CSV or Excel.
It is the lovechild of sql+jq.
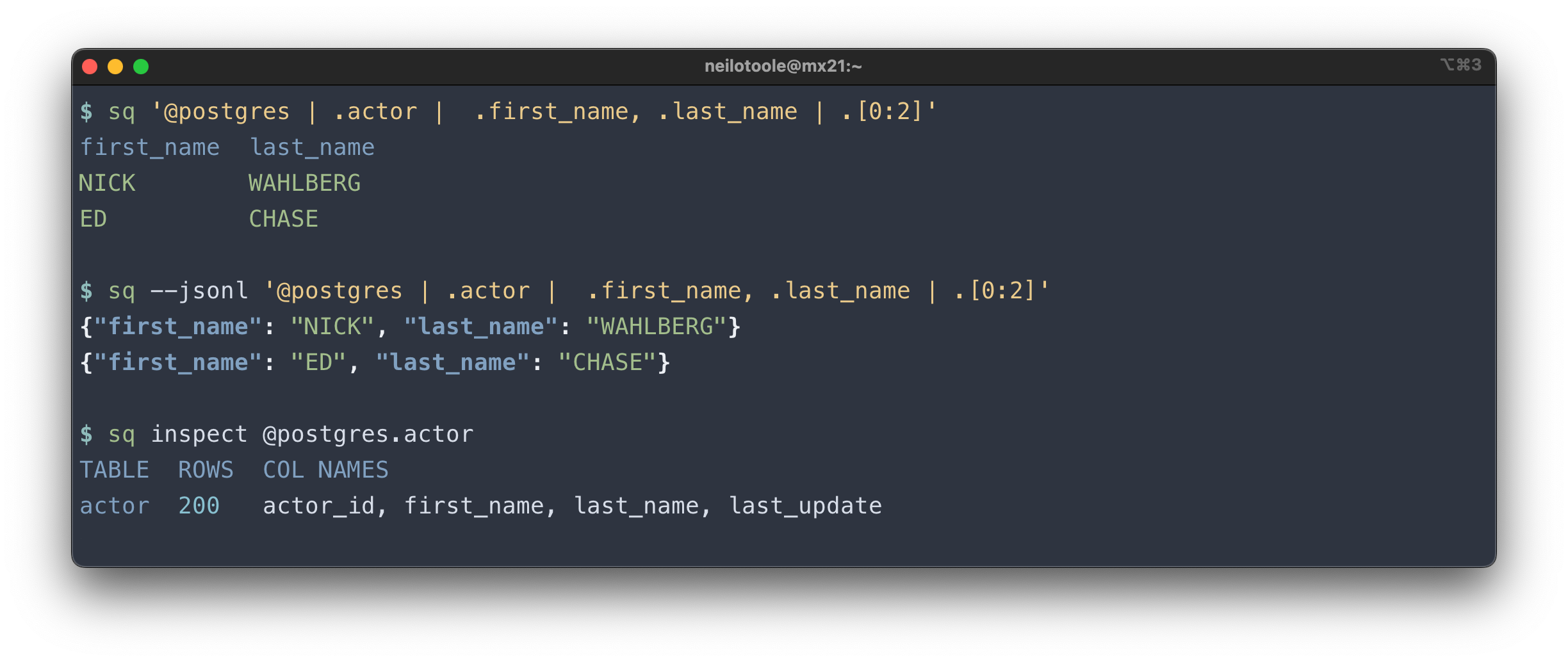
sq executes jq-like queries, or database-native SQL.
It can join across sources: join a CSV file to a Postgres table, or
MySQL with Excel.
sq outputs to a multitude of formats
including JSON,
Excel, CSV,
HTML, Markdown
and XML, and can insert query
results directly to a SQL database.
sq can also inspect sources to view metadata about the source structure (tables,
columns, size). You can use sq diff to compare tables, or
entire databases. sq has commands for common database operations to
copy, truncate,
and drop tables.
Find out more at sq.io.
[!TIP] The rest of this doc is mainly for
sqend users and first-timers. Contributors (bug reports, feature requests, pull requests), see CONTRIBUTING.md.
Drivers
sq knows how to deal with a data source type via a driver
implementation. To view the installed/supported drivers:
$ sq driver ls
DRIVER DESCRIPTION
sqlite3 SQLite
postgres PostgreSQL
sqlserver Microsoft SQL Server / Azure SQL Edge
mysql MySQL
clickhouse ClickHouse
csv Comma-Separated Values
tsv Tab-Separated Values
json JSON
jsona JSON Array: LF-delimited JSON arrays
jsonl JSON Lines: LF-delimited JSON objects
xlsx Microsoft Excel XLSX
[!NOTE] ClickHouse Driver support is currently in beta. Full details of support can be found in the ClickHouse README.
Install
macOS
brew install sq
[!IMPORTANT]
sqis now a core brew formula. Previously,sqwas available viabrew install neilotoole/sq/sq. If you have installedsqthis way, you should uninstall it (brew uninstall neilotoole/sq/sq) before installing the new formula viabrew install sq.
Linux
/bin/sh -c "$(curl -fsSL https://sq.io/install.sh)"
Windows
scoop bucket add sq https://github.com/neilotoole/sq
scoop install sq
Go
go install github.com/neilotoole/sq
Docker
The ghcr.io/neilotoole/sq
image is preloaded with sq and a handful of related tools like jq.
Local
# Shell into a one-time container.
$ docker run -it ghcr.io/neilotoole/sq zsh
# Start detached (background) container named "sq-shell".
$ docker run -d --name sq-shell ghcr.io/neilotoole/sq
# Shell into that container.
$ docker exec -it sq-shell zsh
Kubernetes
Running sq in a Kubernetes environment is useful for DB migrations,
as well as general data wrangling.
# Start pod named "sq-shell".
$ kubectl run sq-shell --image ghcr.io/neilotoole/sq
# Shell into the pod.
$ kubectl exec -it sq-shell -- zsh
See other install options.
Agent skills
An Agent Skills skill for this repo lives under
skills/sq/ and helps coding assistants use an installed sq
(CLI patterns, references/ for drivers). User-facing install and usage are
documented at sq.io/docs/agent-skills.
Quick install from GitHub:
npx skills add neilotoole/sq
Documentation site (sq.io)
User-facing docs at sq.io are built from the site/ directory in this repository (Hugo + Bun + Netlify). To work on the website locally, see site/README.md. The standalone sq-web repository is archived; open issues and pull requests here against neilotoole/sq for doc and site changes.
Overview
Use sq help to see command help. Docs are over at sq.io.
Read the overview, and
tutorial. The cookbook has
recipes for common tasks, and the query guide covers sq's query language.
The major concept is: sq operates on data sources, which are treated as SQL databases (even if the
source is really a CSV or XLSX file etc.).
In a nutshell, you sq add a source (giving it a handle), and then execute commands against the
source.
Sources
Initially there are no sources.
$ sq ls
Let's add a source. First we'll add a SQLite database, but this could also be Postgres, SQL Server etc., or a document source such Excel or CSV.
Download the sample DB, and sq add the source.
$ wget https://sq.io/testdata/sakila.db
$ sq add ./sakila.db
@sakila sqlite3 sakila.db
$ sq ls -v
HANDLE ACTIVE DRIVER LOCATION OPTIONS
@sakila active sqlite3 sqlite3:///Users/demo/sakila.db
$ sq ping @sakila
@sakila 1ms pong
$ sq src
@sakila sqlite3 sakila.db
The sq ping command simply pings the source
to verify that it's available.
sq src lists the active source, which in our
case is @sakila.
You can change the active source using sq src @other_src.
When there's an active source specified, you can usually omit the handle from sq commands.
Thus you could instead do:
$ sq ping
@sakila 1ms pong
[!TIP] Document sources such as CSV or Excel can be added from the local filesystem, or from an HTTP URL.
$ sq add https://acme.s3.amazonaws.com/sales.csv
See the sources docs for more.
Query
Fundamentally, sq is for querying data. The jq-style syntax is covered in
detail in the query guide.
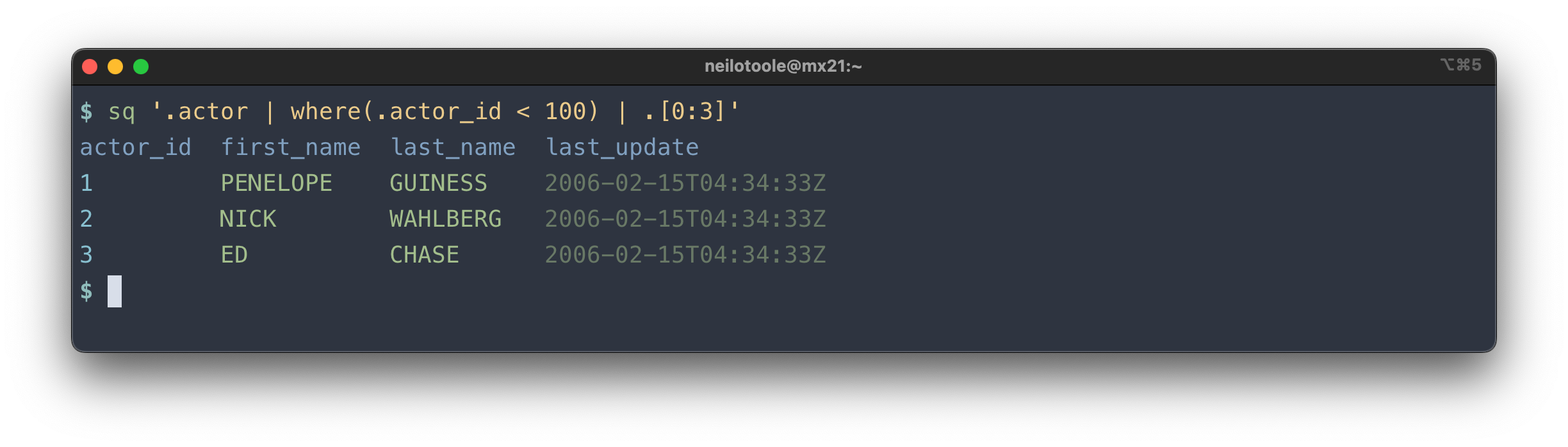
The above query selected some rows from the actor table. You could also
use native SQL, e.g.:
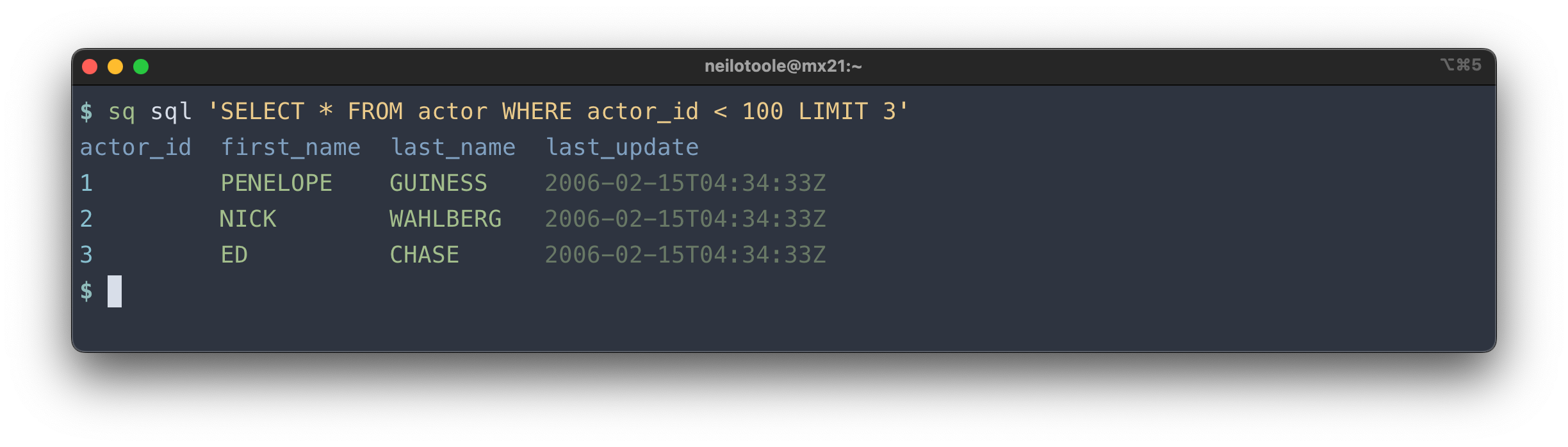
But we're flying a bit blind here: how did we know about the actor table?
Inspect
sq inspect is your friend.
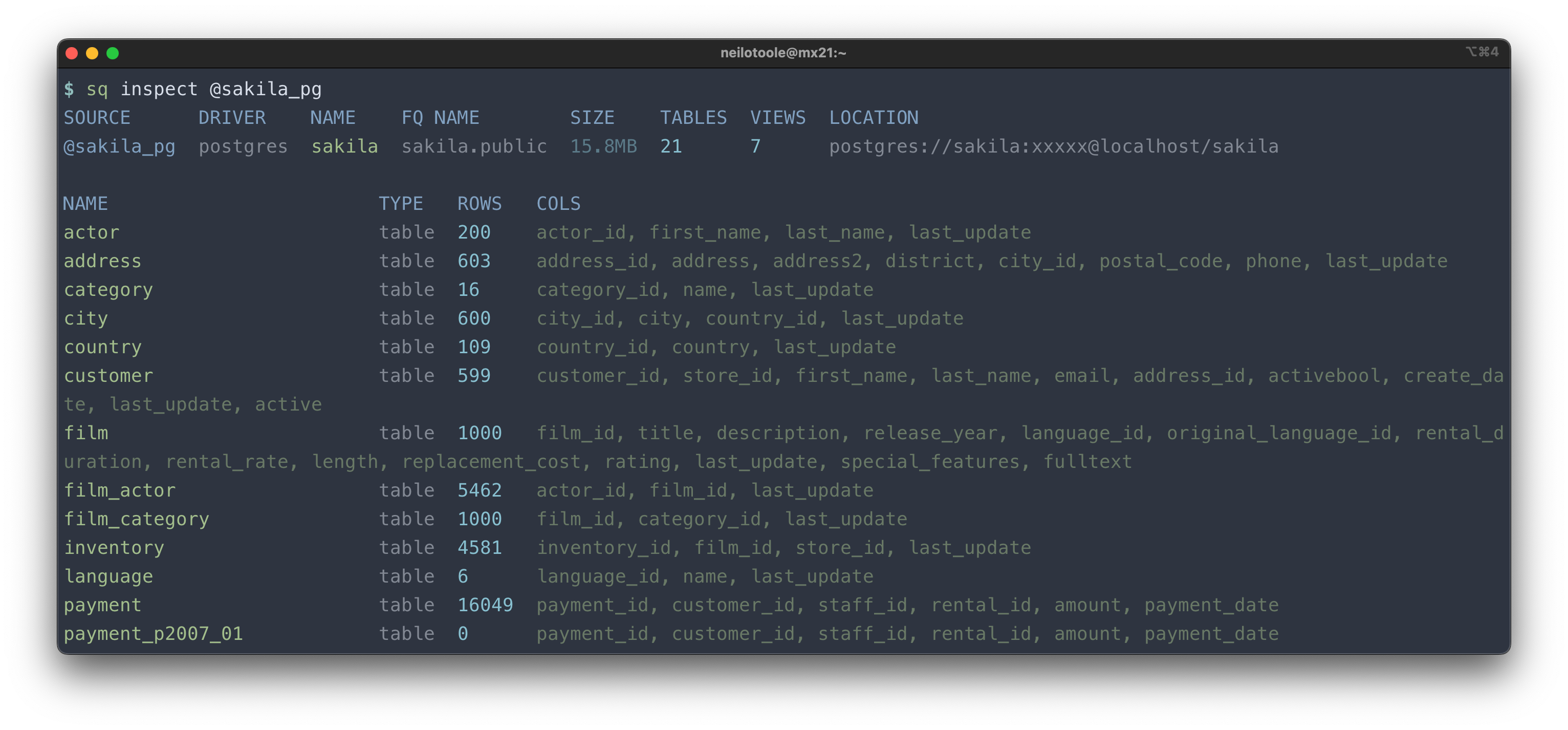
Use sq inspect -v to see more detail.
Or use -j to get JSON output:
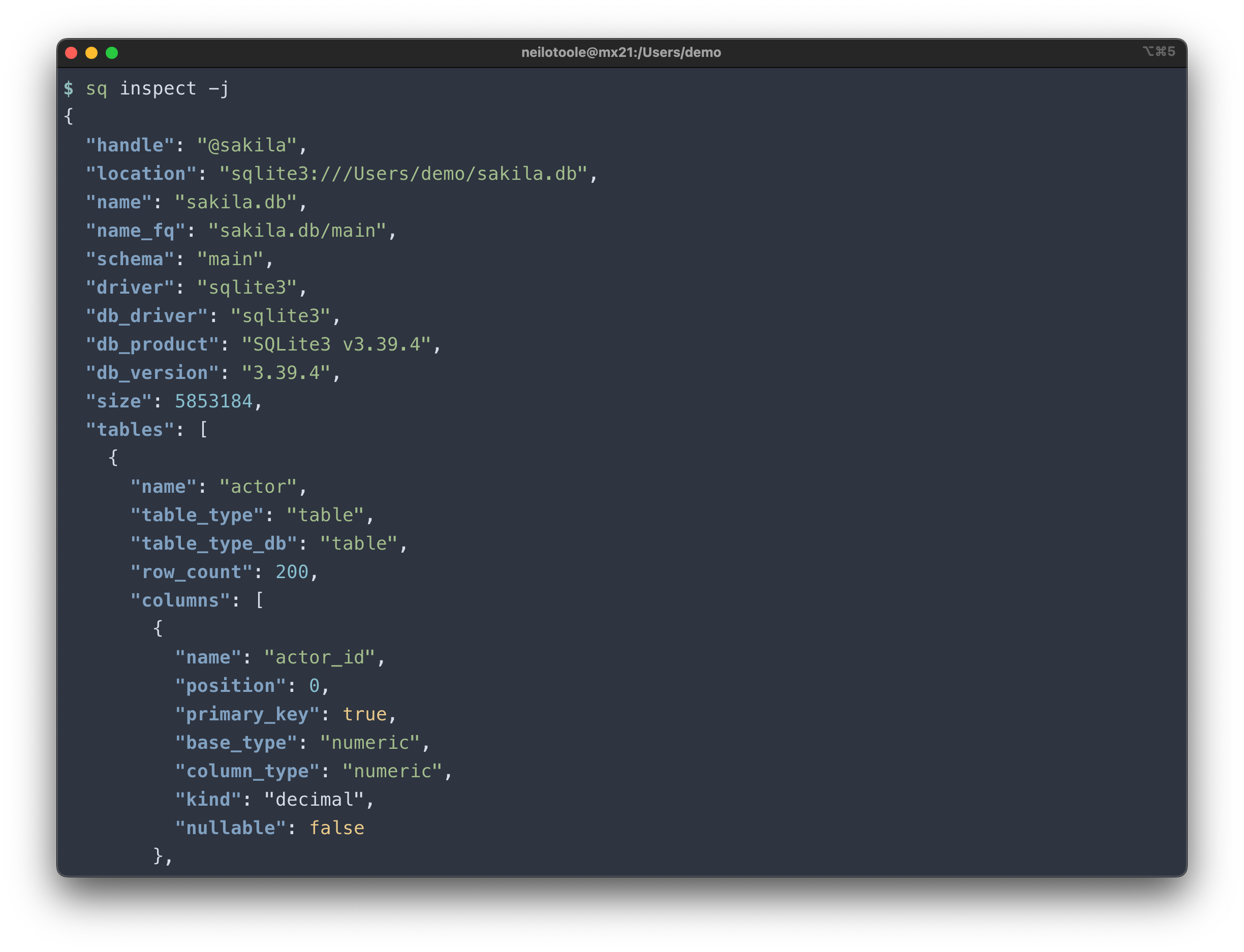
Combine sq inspect with jq for some useful capabilities.
Here's how to list
all the table names in the active source:
$ sq inspect -j | jq -r '.tables[] | .name'
actor
address
category
city
country
customer
[...]
And here's how you could export each table to a CSV file:
$ sq inspect -j | jq -r '.tables[] | .name' | xargs -I % sq .% --csv --output %.csv
$ ls
actor.csv city.csv customer_list.csv film_category.csv inventory.csv rental.csv staff.csv
address.csv country.csv film.csv film_list.csv language.csv sales_by_film_category.csv staff_list.csv
category.csv customer.csv film_actor.csv film_text.csv payment.csv sales_by_store.csv store.csv
Note that you can also inspect an individual table:
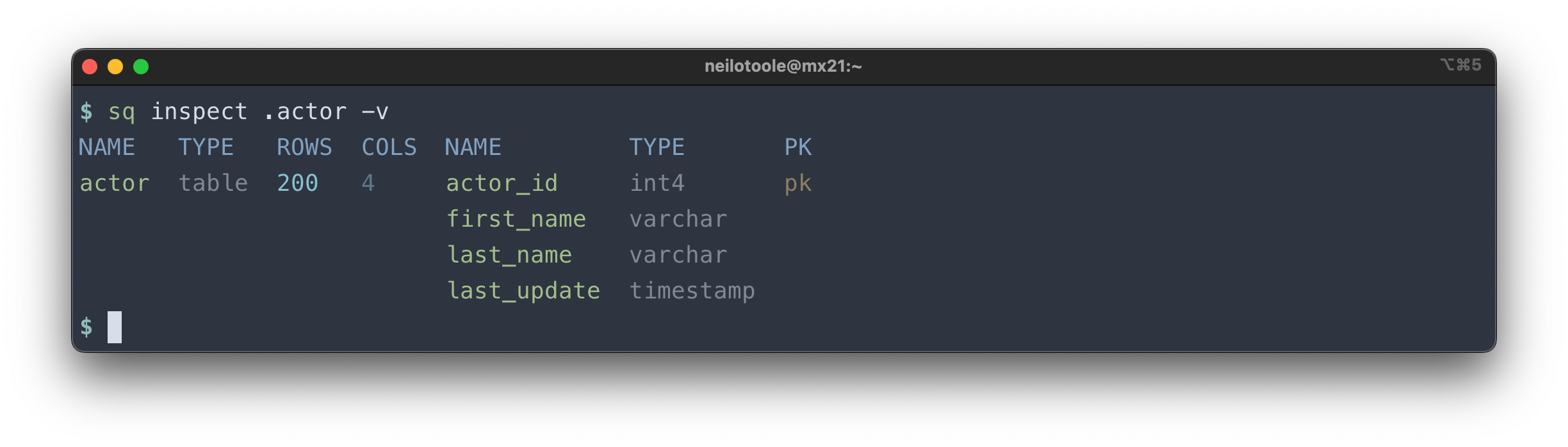
Read more about sq inspect.
Diff
Use sq diff to compare metadata, or row data, for sources, or individual tables.
The default behavior is to diff table schema and row counts. Table row data is not compared in this mode.
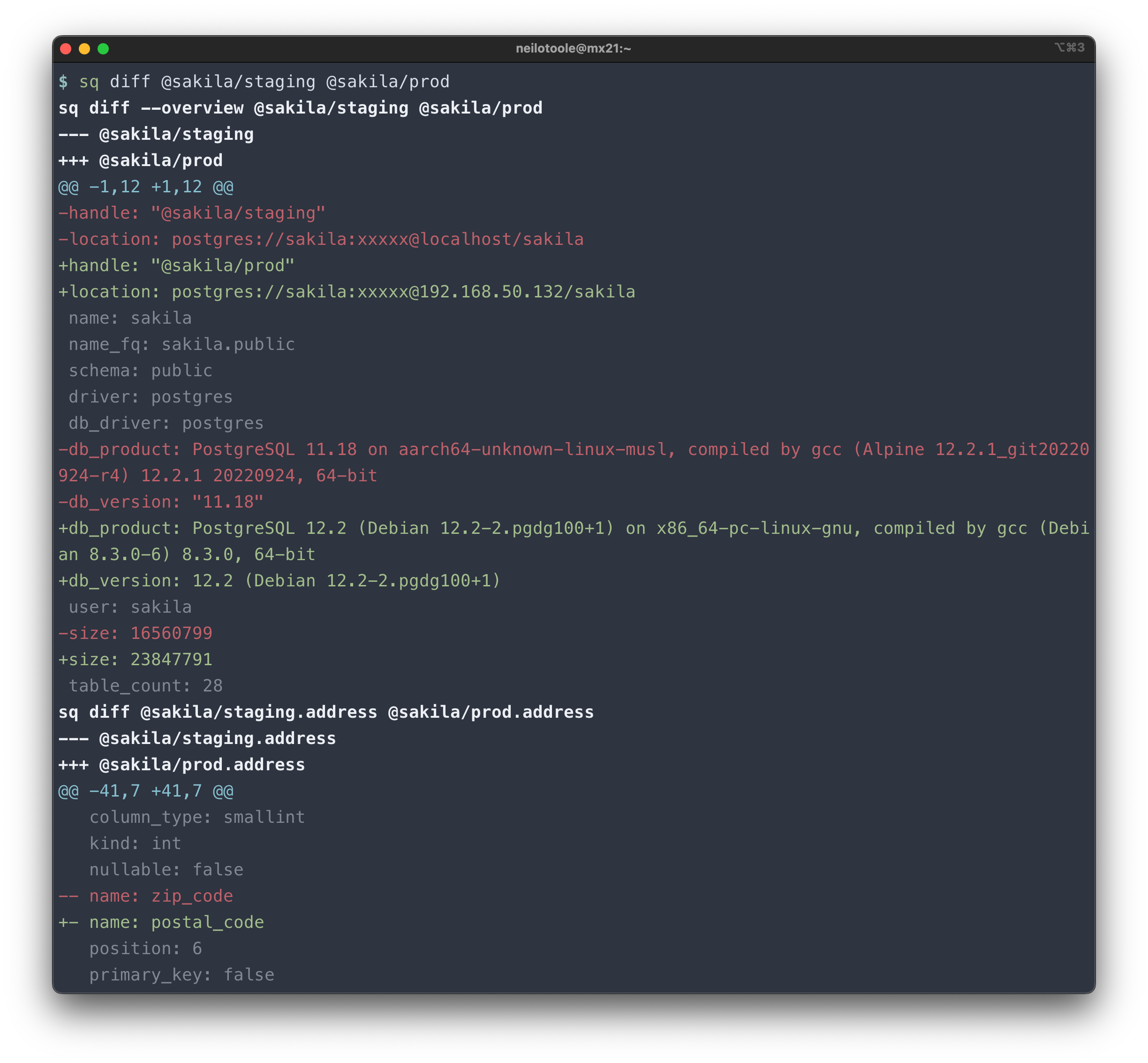
Use --data to compare row data.
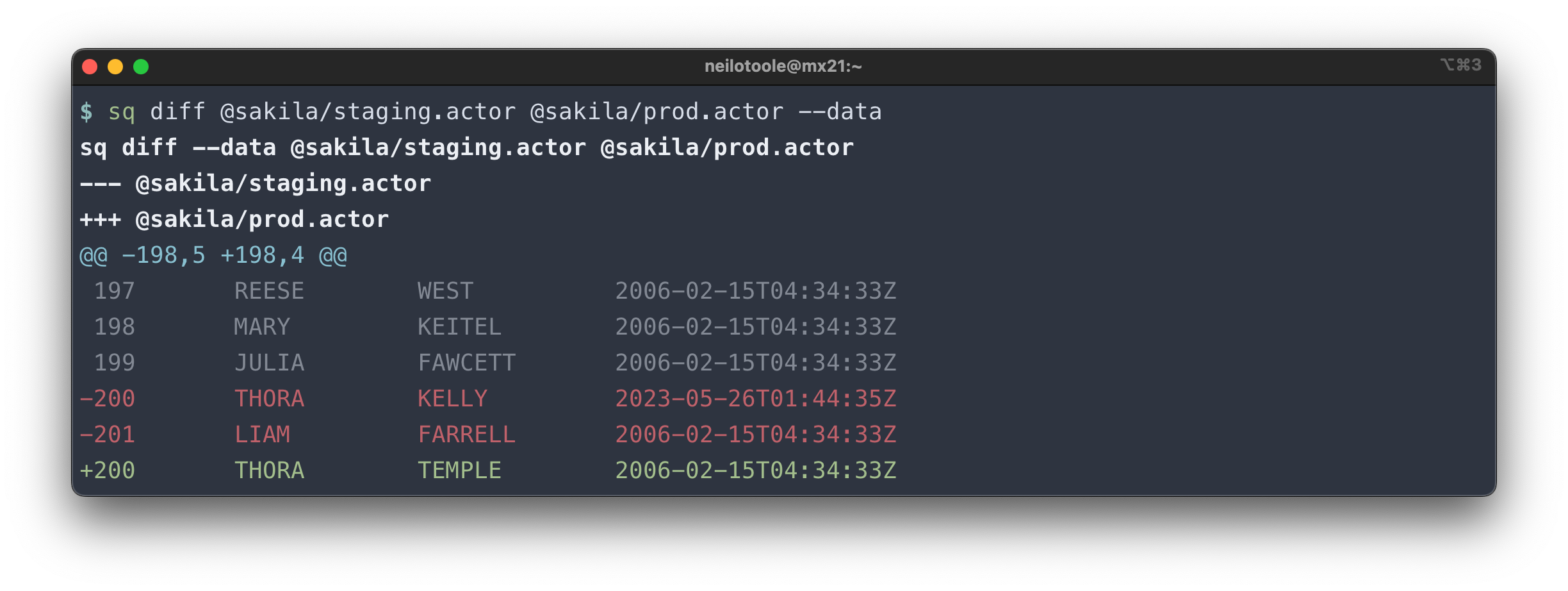
There are many more options available. See the diff docs.
Insert query results
sq query results can be output in various formats
(text,
json,
csv, etc.). Those results can also be "outputted"
as an insert into a database table.
That is, you can use sq to insert results from a Postgres query into a MySQL table,
or copy an Excel worksheet into a SQLite table, or a push a CSV file into
a SQL Server table etc.
[!TIP] If you want to copy a table inside the same (database) source, use
sq tbl copyinstead, which uses the database's native table copy functionality.
Here we query a CSV file, and insert the results into a Postgres table.
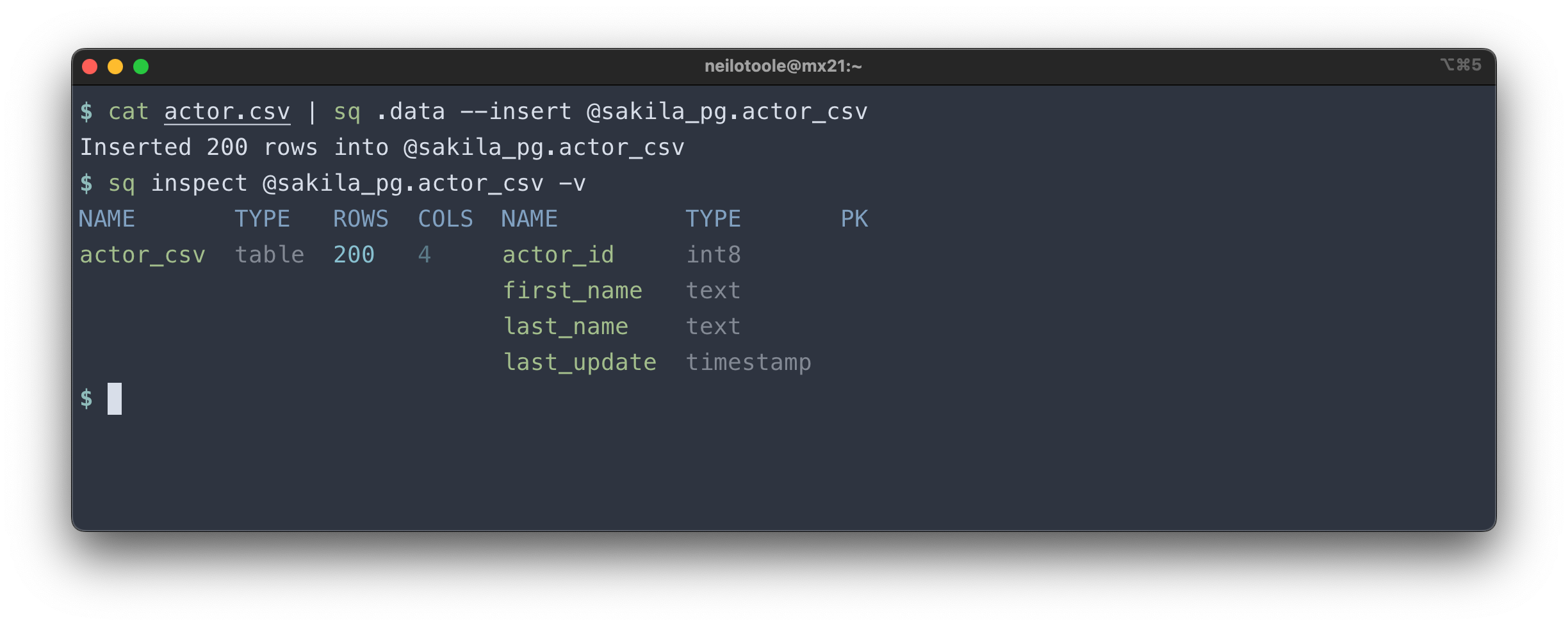
Cross-source joins
sq can perform the usual joins. Here's how you would
join tables actor, film_actor, and film:
$ sq '.actor | join(.film_actor, .actor_id) | join(.film, .film_id) | .first_name, .last_name, .title'
But sq can also join across data sources. That is, you can join an Excel worksheet with a
Postgres table, or join a CSV file with MySQL, and so on.
This example joins a Postgres database, an Excel worksheet, and a CSV file.
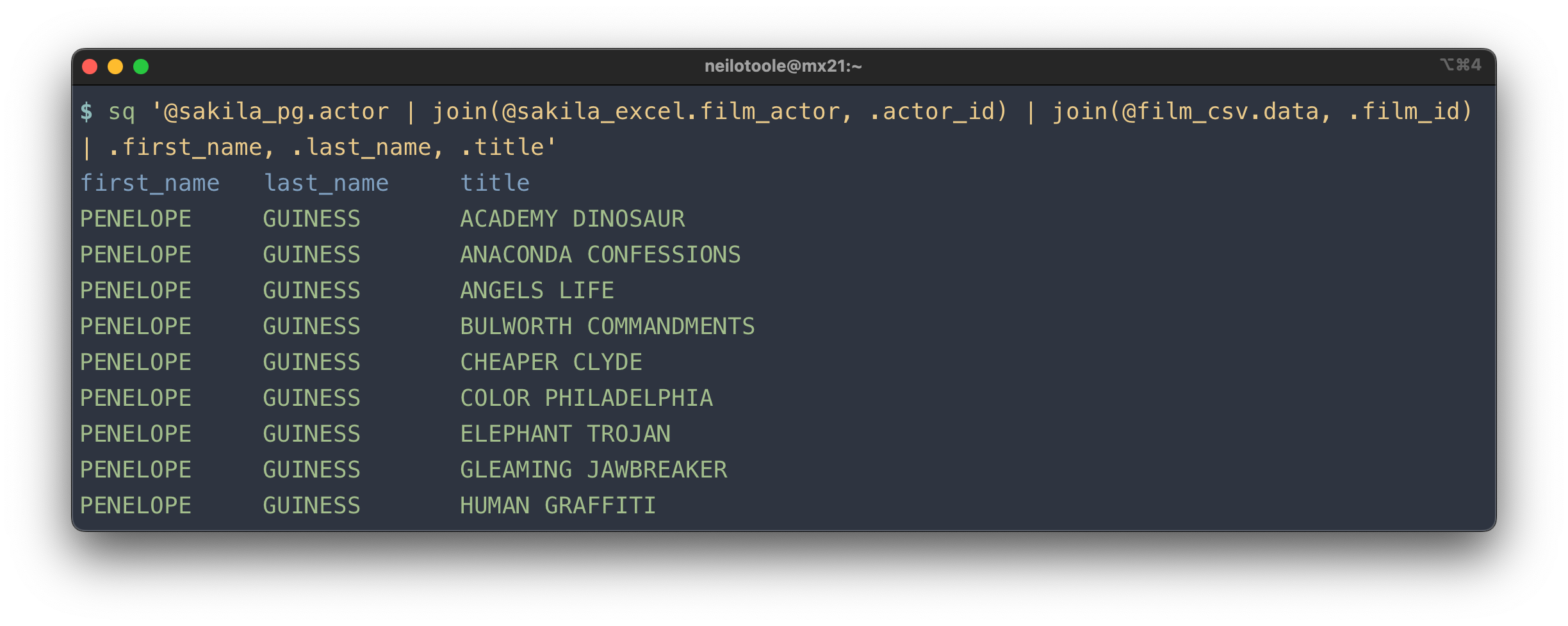
Read more about cross-source joins in the query guide.
Table commands
sq provides several handy commands for working with tables:
tbl copy, tbl truncate
and tbl drop.
Note that these commands work directly
against SQL database sources, using their native SQL commands.
$ sq tbl copy .actor .actor_copy
Copied table: @sakila.actor --> @sakila.actor_copy (200 rows copied)
$ sq tbl truncate .actor_copy
Truncated 200 rows from @sakila.actor_copy
$ sq tbl drop .actor_copy
Dropped table @sakila.actor_copy
UNIX pipes
For file-based sources (such as CSV or XLSX), you can sq add the source file,
but you can also pipe it:
$ cat ./example.xlsx | sq .Sheet1
Similarly, you can inspect:
$ cat ./example.xlsx | sq inspect
Output formats
sq has many output formats:
--text: Text--json: JSON--jsona: JSON Array--jsonl: JSON Lines--csv/--tsv: CSV / TSV--xlsx: XLSX (Microsoft Excel)--html: HTML--xml: XML--yaml: YAML--markdown: Markdown--raw: Raw (bytes)
Contributing
See CONTRIBUTING.md.
CHANGELOG
See CHANGELOG.md.
Acknowledgements
- Thanks to Diego Souza for creating
the Arch Linux package, and
@icpfor creating the Void Linux package. - Much inspiration is owed to jq.
- See
go.modfor a list of third-party packages. sqimports a bunch ofusqlfunctionality.- Additionally,
sqincorporates modified versions of: olekukonko/tablewritersegmentio/encodingfor JSON encoding.- The Sakila example databases were lifted from jOOQ, which in turn owe their heritage to earlier work on Sakila.
- Date rendering via
ncruces/go-strftime. - A modified version
dolmen-go/contextiois incorporated into the codebase. djherbis/bufferis used for caching.- A forked version of
nightlyone/lockfileis incorporated. - The human-friendly
textlog format handler is a fork oflmittmann/tint.
Similar, related, or noteworthy projects
usqltextqlgolang-migrateoctosqlrqmillerjsoncoloris a JSON colorizer created forsq.streamcacheis a Go in-memory byte cache mechanism created forsq.fifomuis a FIFO mutex, used bystreamcache, and thus upstream insq.tailbufis a fixed-size object tail buffer created forsq.oncecacheis an in-memory object cache created forsq.